刚听了南风的引流课,相信现在SEO 对于大家肯定都不陌生吧,但 Technical SEO 我相信很多人都不太了解,其实就是利用一些技术手段去优化网站的速度、结构、安全性和使用体验等,提升你的网站在搜索引擎中的排名,让 ...
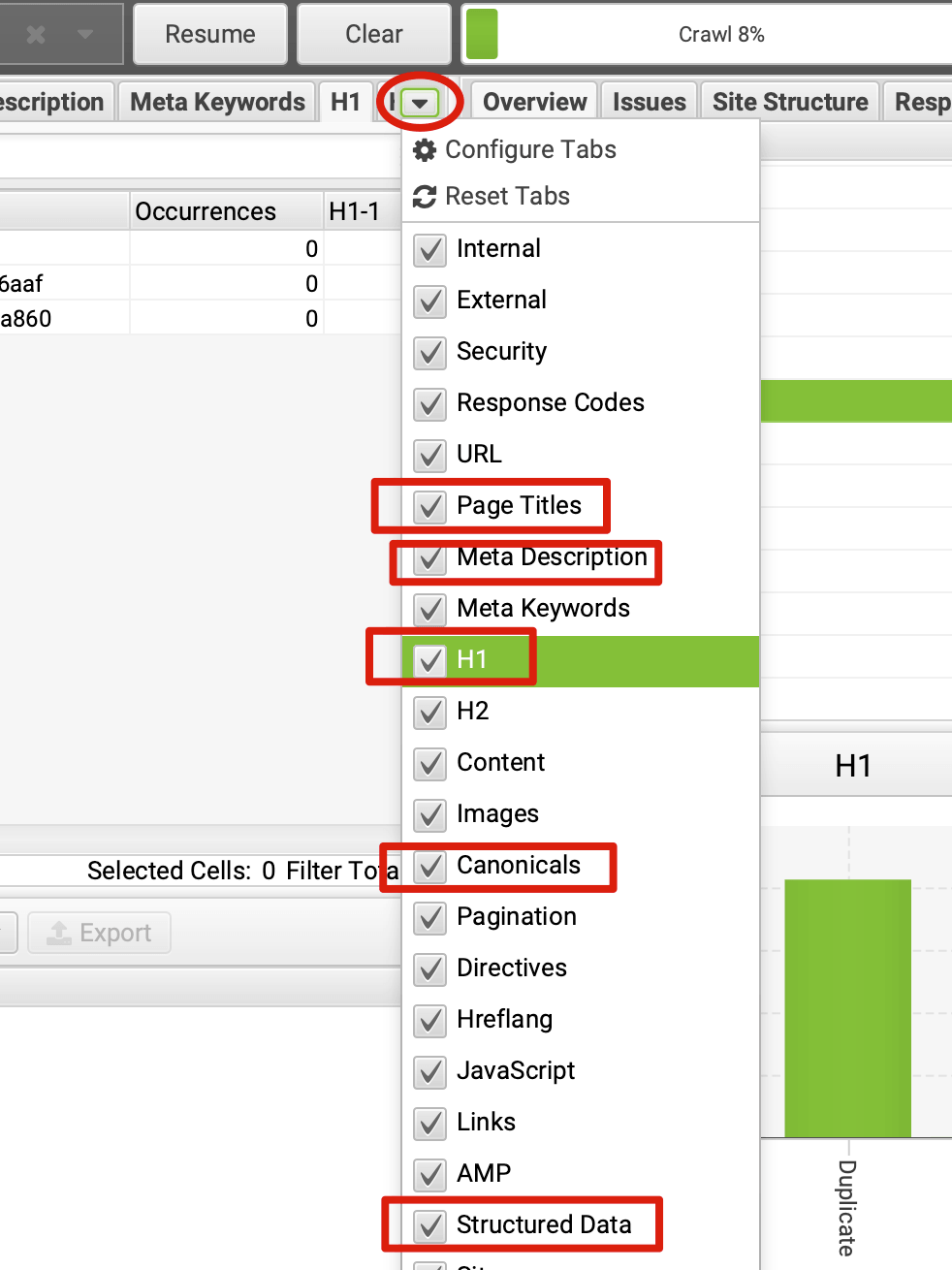
刚听了南风的引流课,相信现在SEO 对于大家肯定都不陌生吧,但 Technical SEO 我相信很多人都不太了解,其实就是利用一些技术手段去优化网站的速度、结构、安全性和使用体验等,提升你的网站在搜索引擎中的排名,让用户能够第一眼看到你的网站。 Technical SEO 怎么去操作?下面,我将从这 6 个方面分享英文网站的 Technical SEO 优化: (1)什么是 Technical SEO (2)为什么要做 Technical SEO (3)Technical SEO 的一些基本概念 (4)Technical SEO 优化的5个核心点 (5)Screaming Frog 爬虫配置及使用 SOP (6)Technical SEO 优化中的一些技巧和工具分享 大家好, 我是阿宇雨鱼昱玉, 上次给大家分享了ChatGPT的个人见解本次分享主要来自我工作中的一些实操经验和体会, 希望可以给 SEO 新人带来一点启发, 也请大佬多多指点。 PS: 本文中的 Technical SEO 特指 Google SEO 里的 Technical SEO, 后面不再说明 一、什么是 Technical SEO Technical SEO 又叫技术 SEO, 它属于 SEO 里的一部分, 主要关注网站的技术方面,包括网站的速度、结构、安全性、可访问性和代码质量等方面。 这些技术方面可能不容易被普通用户察觉到,但它们对于搜索引擎来说非常重要。 二、为什么要做 Technical SEO 想象一下,当您在互联网上搜索一些内容时,比如您想了解如何做蛋糕,您会在搜索引擎中输入相关的关键字。 搜索引擎会自动找到和您的搜索相关的网站和页面,并将这些结果按照相关度和质量排序。这个排序的过程就是搜索引擎优化,而技术性 SEO 就是其中的一种。 现在假设您的网站是一个蛋糕教学网站,您想要让更多的人在搜索引擎中找到您的网站并学习做蛋糕。 如果您的网站没有做好技术性SEO优化,搜索引擎可能会忽略您的网站或者排名很低,用户就很难找到您的网站了。 比如,如果你的网站的网页加载速度很慢,用户就需要等待很长时间才能看到网页的内容,这可能会让用户失去耐心并离开您的网站,这会让用户不满意并离开您的网站,这会影响您的排名和可见性。 或者,如果您的网站结构混乱或者代码质量较低,那么搜索引擎就会很难识别和理解您的网站内容,从而影响您的排名和可见性。 因此,做好技术性 SEO 优化就像您在做蛋糕时要注意每一个步骤和细节一样,只有当您的网站在技术方面做得好,搜索引擎才能更好地理解和展示您的网站内容,提高网站的排名, 使更多的用户找到您的网站,从而提高您的业务增长和收益。 三、Technical SEO 的一些基本概念 (1)SEO 的基本概念 搜索引擎优化(SEO)是指通过优化网站的内容和结构,以及提高网站的权威度和可访问性等方式,来提高网站在搜索引擎中的排名和可见性。 (2)Googlebot Googlebot 是 Google 搜索引擎的爬虫程序,负责定期访问网站并抓取网页的内容,以便在搜索引擎中建立索引。 (3)robots.txt robots.txt 是一种文本文件,用于告诉搜索引擎哪些页面不应该被抓取或索引。网站管理员可以使用 robots.txt 来控制搜索引擎爬虫程序的访问。 (4)sitemap.xml sitemap.xml 是一种XML文件,列出了网站中所有页面的 URL 地址,帮助搜索引擎更好地抓取网站的内容。网站管理员可以在 Sitemap 中指定页面的优先级和更新频率。 (5)抓取 抓取是指搜索引擎爬虫程序访问网站并下载网页内容的过程。 (6)索引(或收录) 索引是指搜索引擎将抓取的网页内容存储在其数据库中,并根据关键词和其他信号对其进行分类和排序的过程。当用户搜索相关关键词时,搜索引擎将使用这些索引来返回相关结果。 (7)爬虫工具 爬虫工具是一种可以模拟搜索引擎爬虫程序访问网站并获取网站数据的工具,帮助网站管理员了解网站的技术问题和SEO优化机会。 (8)面包屑 面包屑是一种网站导航元素,通常在页面顶部显示,并显示用户在网站中的位置和路径。面包屑可以帮助用户理解网站的结构和组织。 (9)结构化数据 结构化数据是一种格式化的数据,以特定的标记和语法表示,用于帮助搜索引擎更好地理解网站内容。结构化数据可以用于标记网站中的各种信息,如产品、事件、地点、评价等,以便在搜索结果中显示更多有用信息。 四、Technical SEO 优化的5个核心点
(1)爬取网站 1、检查网站结构 在爬取网站前, 首先要了解并熟悉网站结构(页面分类, 页面路径URL, 顶部、底部导航栏, 侧边栏, 面包屑等) 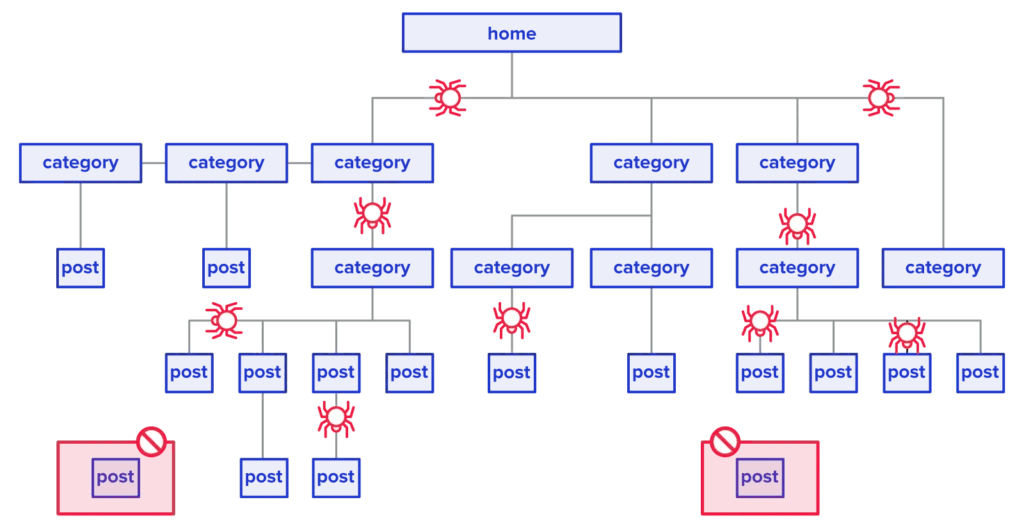 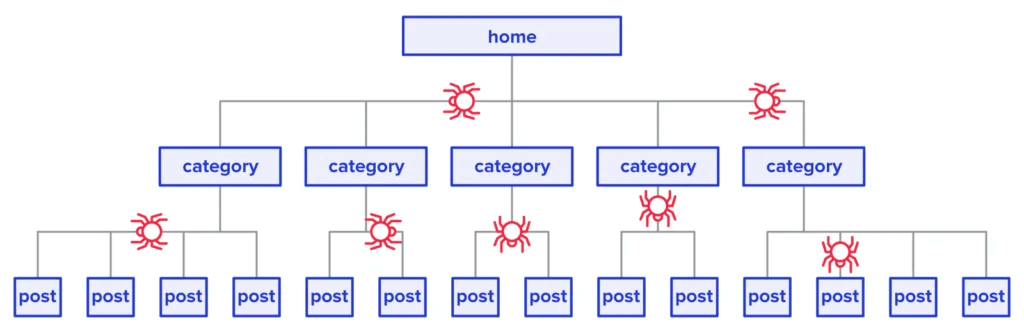 2、爬取网站 设置爬虫工具,爬取网站的测试环境和正式环境. 爬虫工具我们用的付费的 Screaming Frog SEO Spider , 爬虫可以批量检查多个页面的是否有 404, 500 以及页面的元素 (2)检查页面 爬虫爬取网站后, 通常会检查页面的两个方面: 页面状态和页面元素 1、页面状态
除了200, 其他的常见的404, 500, 308 问题要及时修复 2、页面元素
如果是检查页面的元素, 推荐用这个 Chrome 插件: Detailed SEO Extension 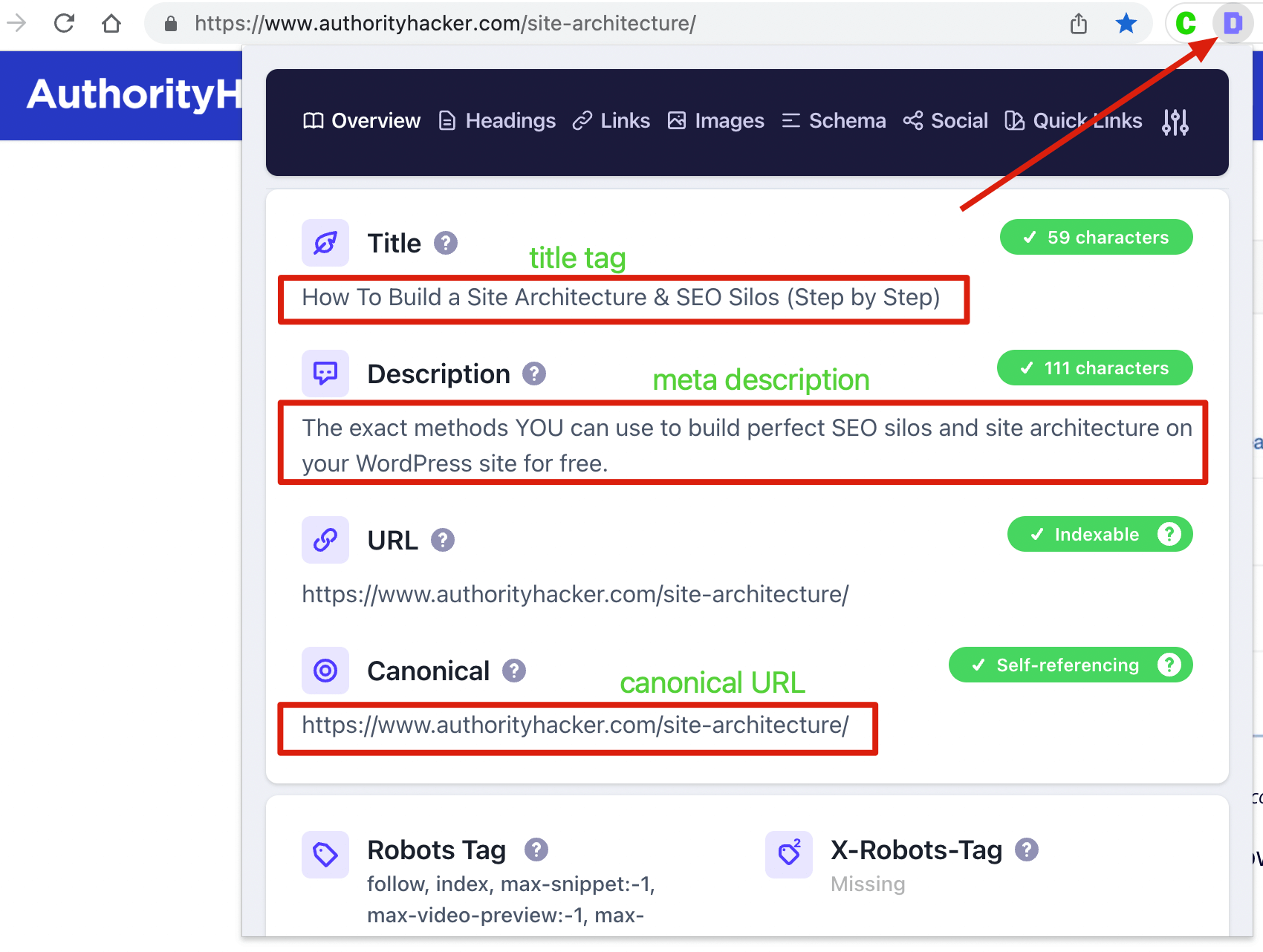 检查页面的 H 标签, 比如 H1, H2, H3 等 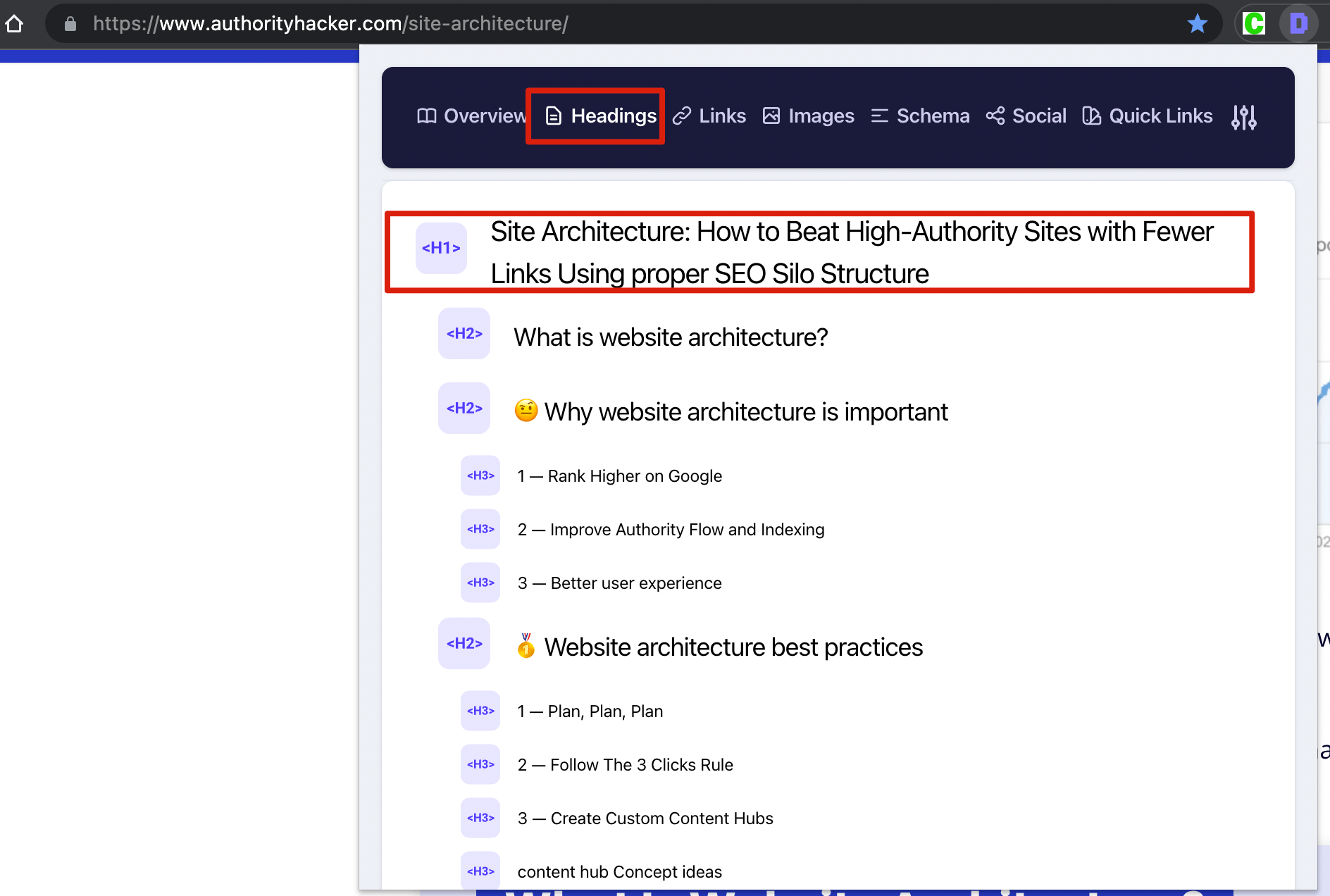 检查页面的结构化数据 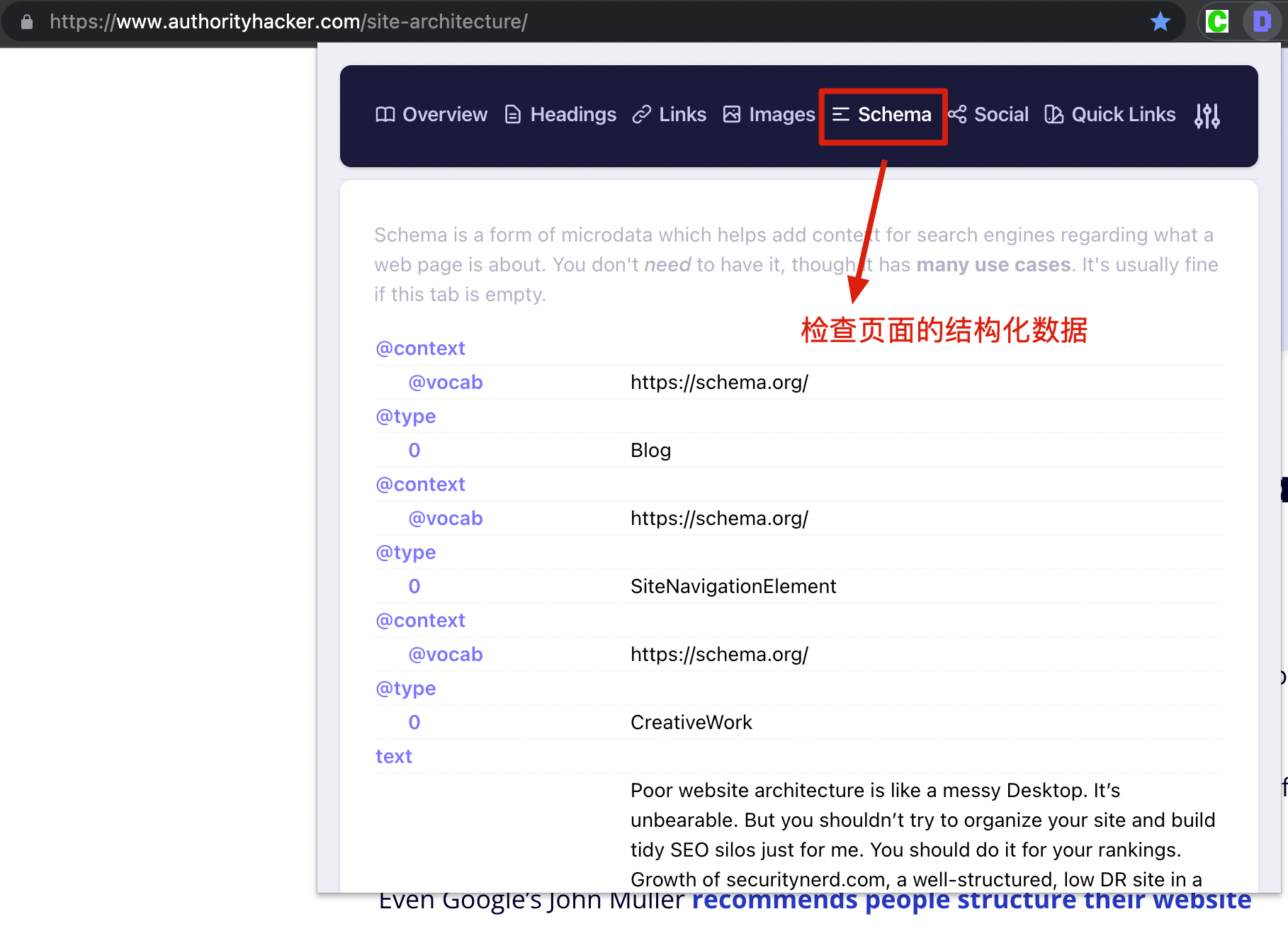 如果要一次性批量查看多个页面的 Canonical URL 是否正确, 推荐这个 Chrome 插件: Inspect Canonical 这个插件的图标(或 icon) 是一个大写的字母 "C", 如果图标的颜色显示这种绿色, 则表示该页面的 canonical URL 正确, 反之, 如果是其他颜色, 比如红色表示该页面的 canonical URL 缺失, 橙色表示 canonical URL 不正确  (3)提交sitemap 和页面收录 一般首页上线后, 借助工具生成 sitemap.xml, robots.txt 文件并上传到网站的根目录, 在线可访问. 1、创建 sitemap.xml 可以用这个在线工具 XML Sitemaps Generator 生成网站的 sitemap.xml 文件, 免费版本最多可以生成含500个URL 的 sitemap.xml 文件 2、创建 robots.txt 手动创建一个文件名为 robots.txt 的 txt 格式文件, 一般填入 下面3行信息 User-Agent: * Allow: / Sitemap: https://test.com/sitemap.xml PS: robots.txt 里记得填网站的 sitemap URL, 比如下面这个网站的 robots.txt 文件, 方便谷歌爬虫读取 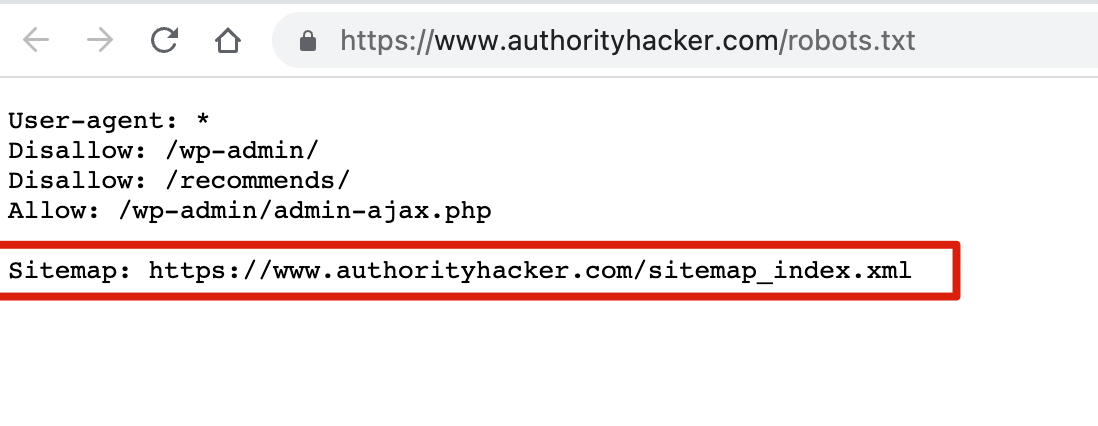 3、提交 sitemap.xml  图片来源网络 4、提交页面收录 在顶部输入框输入要提交收录页面的 URL 并回车  点击这里的 “Request Indexing” 提交收录 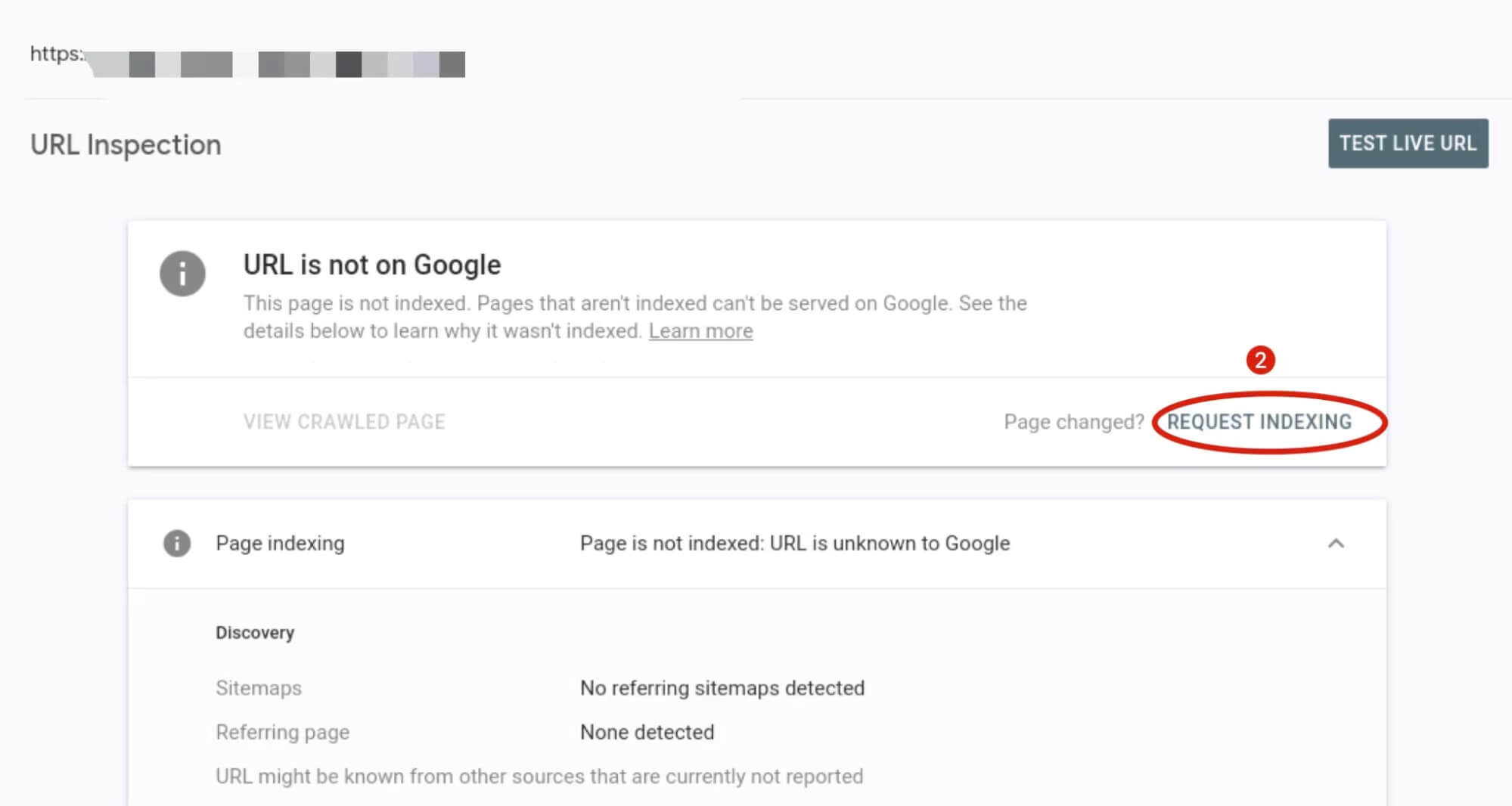 这里出现打勾的图标表示提交成功  (4)网站监控 GSC 后台定期查看页面收录情况及反馈的问题, 及时修复. 1、 查看页面收录情况 点击 GSC 后台左边侧边栏的 "Pages" 选项即可查看收录和未收录页面的情况 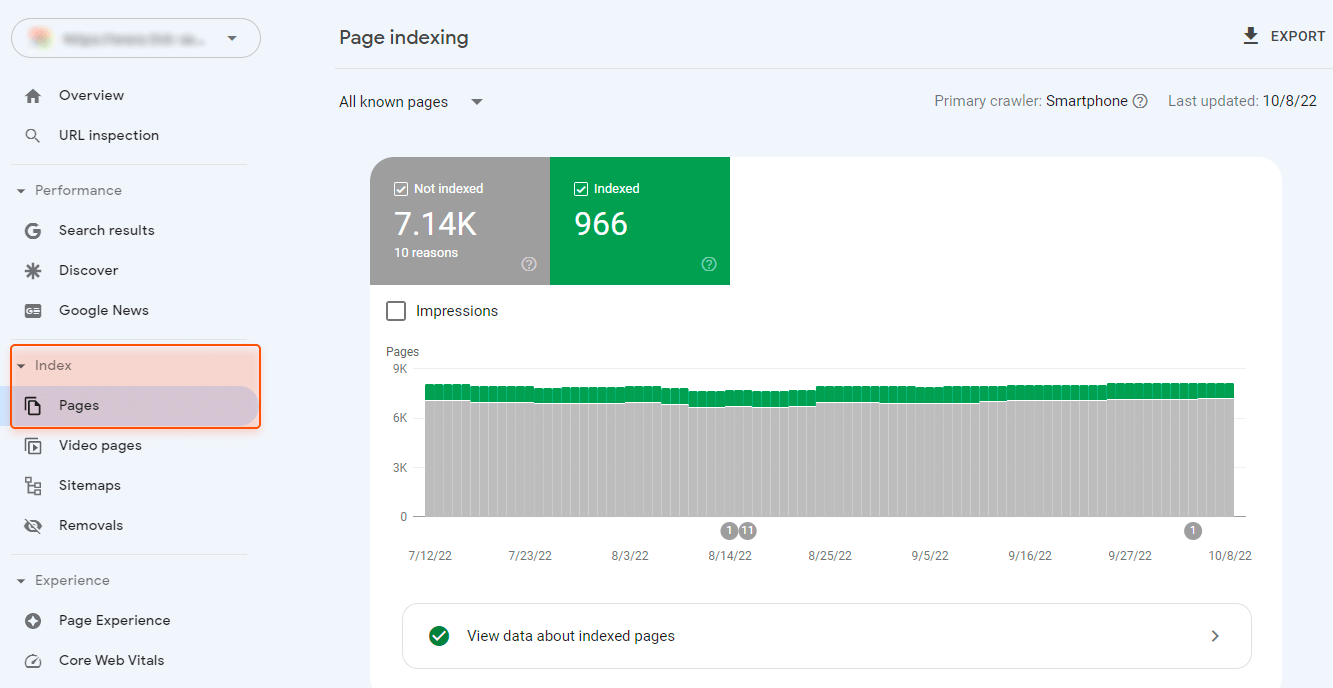 2、检查页面未收录的原因  一般主要是 404 问题居多, 点击查看这些 404 页面并寻找来源页面 PS: 谷歌爬虫收录你的网站的页面要经过这3个过程: 发现(Discover) -> 爬取(Crawl) -> 收录(Indexed) 3、 检查核心网页指标 核心网页指标 (Core Web Vitals) 是谷歌官方开发的一套专门用于衡量用户体验的指标, 网站所有者和SEO人员可以使用这些指标来了解谷歌对他们网站的用户体验的看法。 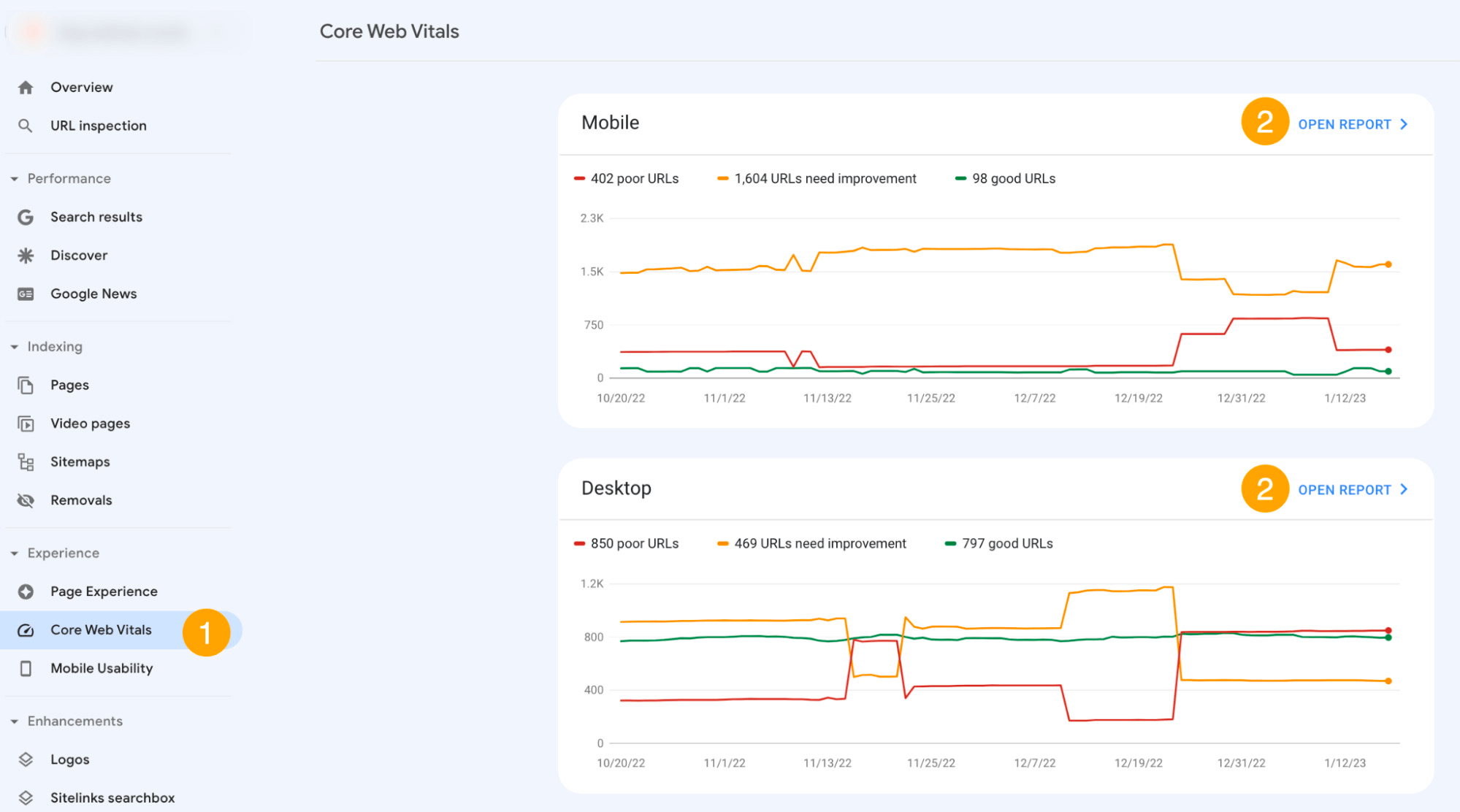 移动端常见的 2 个问题: 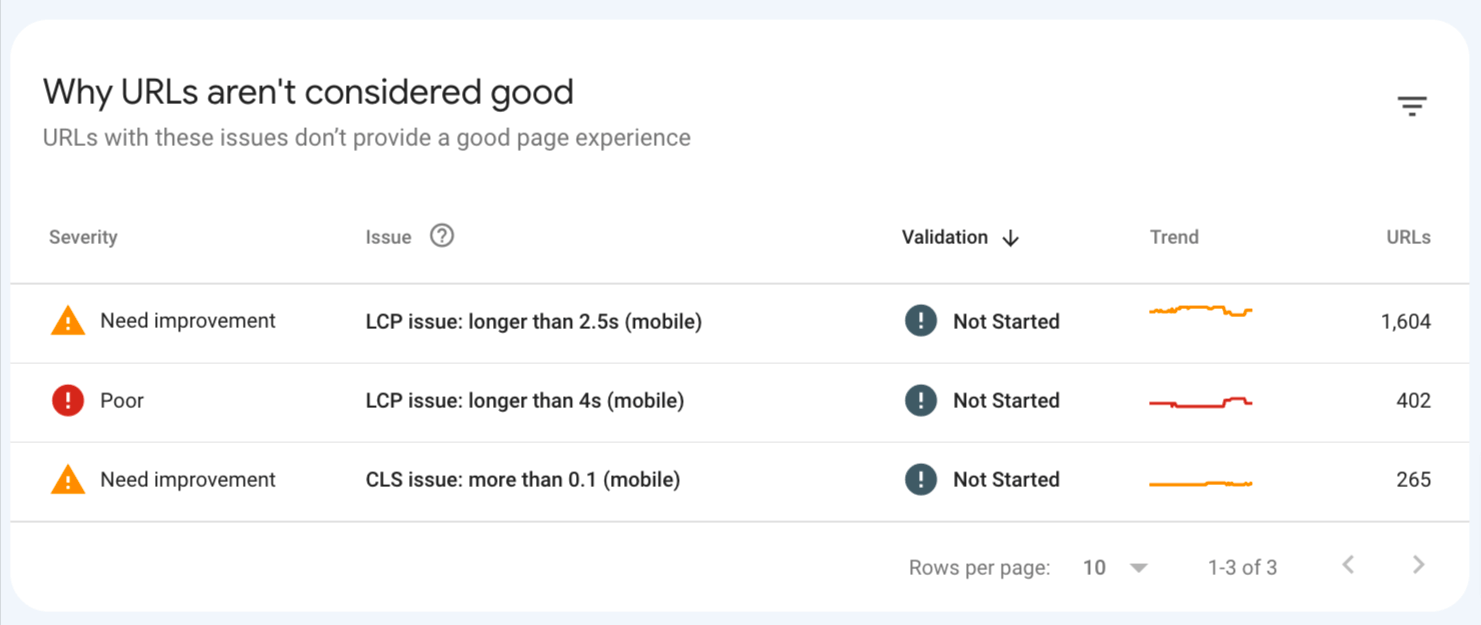 虽然页面体验可以成为排名的一个细微因素,但是您只需要在所有三个类别(页面加载、页面交互和视觉稳定性)中获得“良好”的评分即可。  核心 Web 指标的测量工具: https://web.dev/i18n/zh/vitals-tools/ 4、检查爬取报告 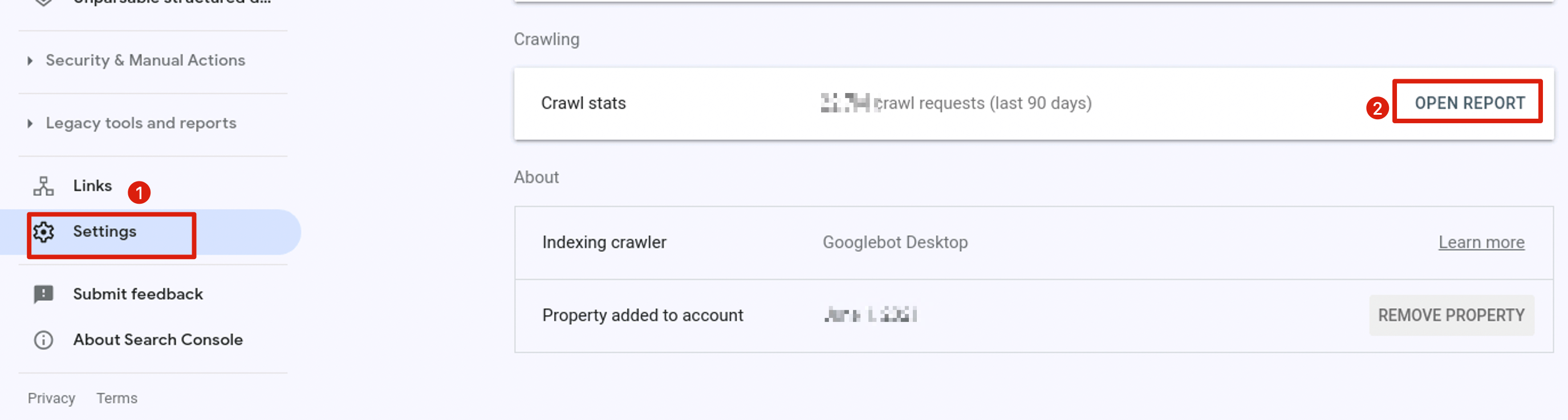 下图可以了解爬虫爬取的频率, 折线陡峭上升的表示该时间段内爬虫爬取速度较快 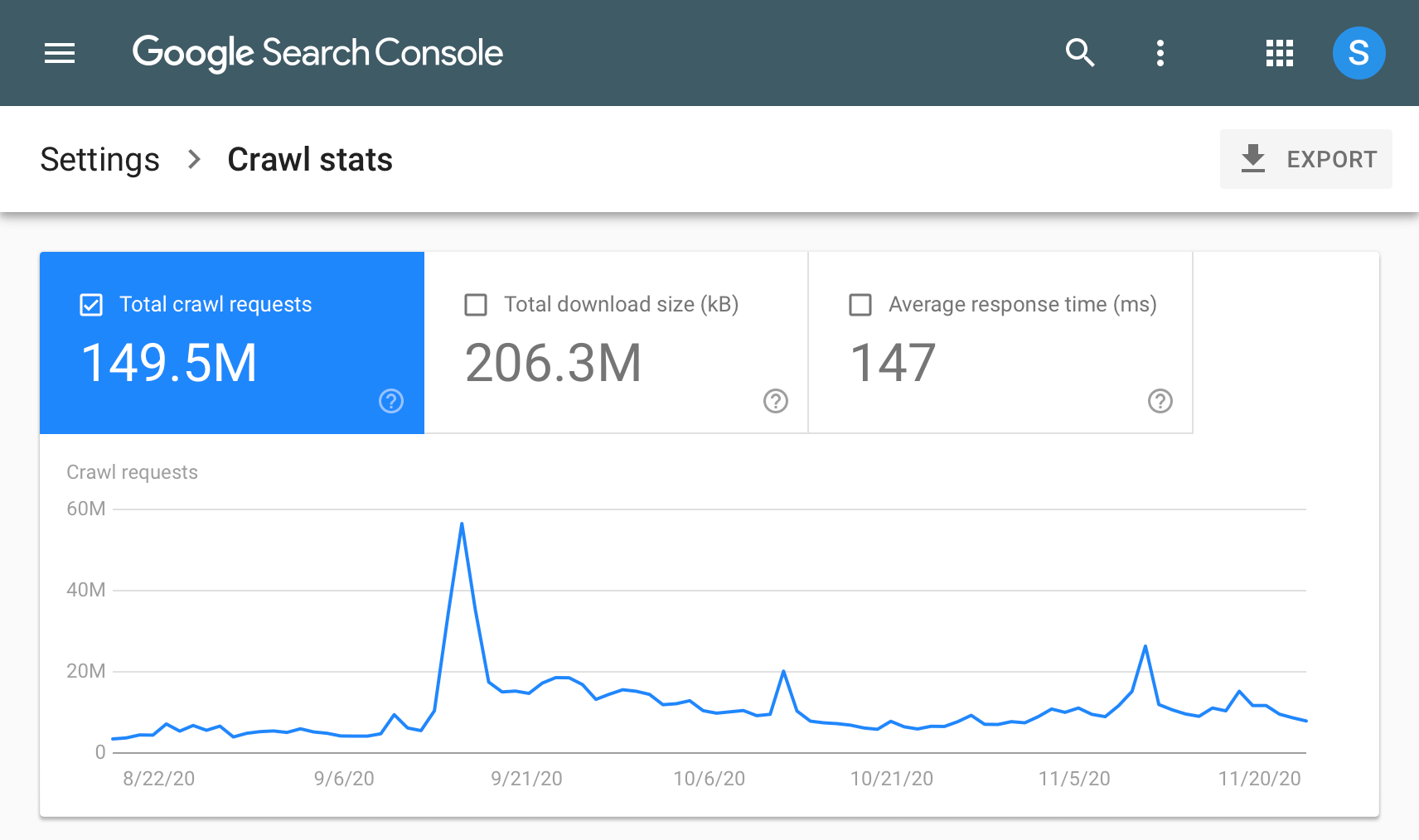 重点看下报告里的 404 问题, 查看这些 404 页面的来源页面并修复 404 链接 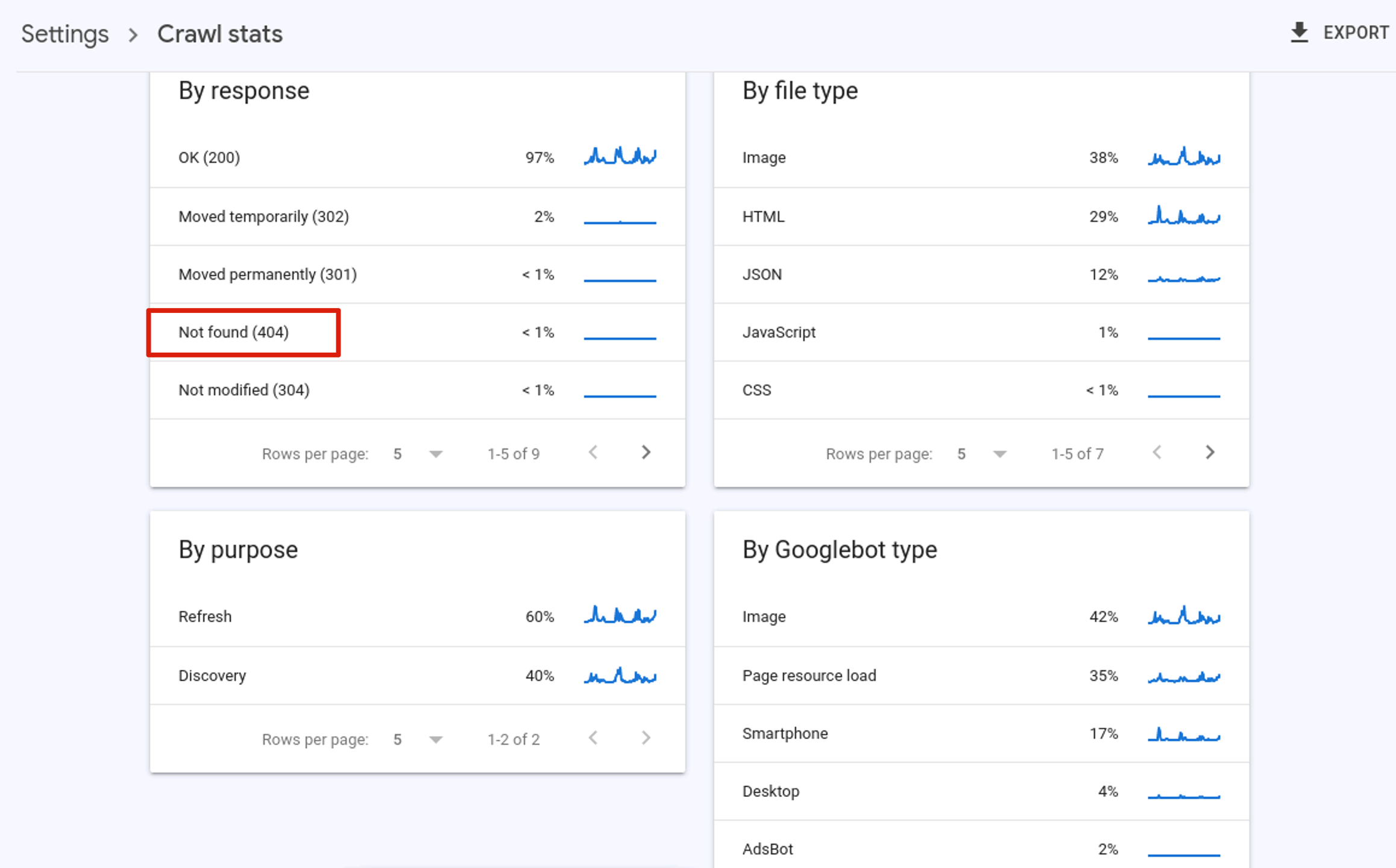 检查 404 链接的来源页面及 sitemap 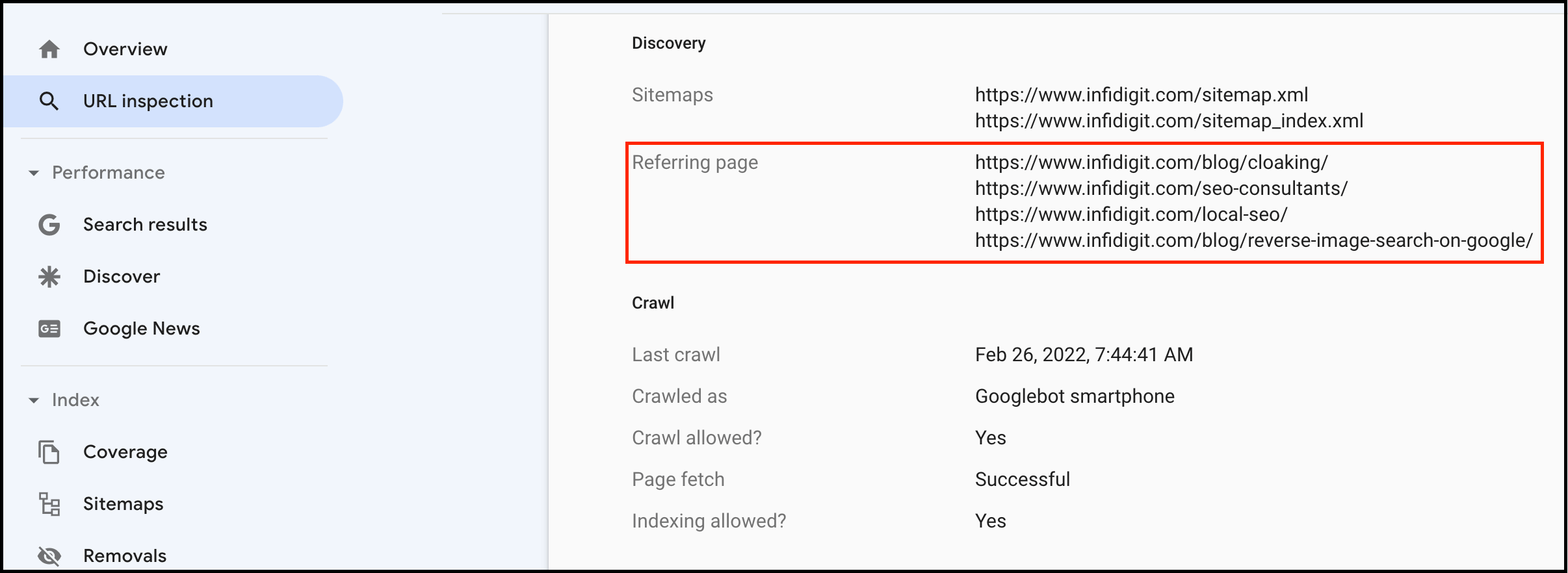 图片来源网络 网站有更新(新增或删除页面, 图片, 链接调整等), 用爬虫扫描, 检查并及时修复问题, 更新 sitemap.xml 重新在 GSC 后台提交, 同时新增或更新的页面提交谷歌收录 如果页面或sitemap 有更新, 要及时同步 sitemap 里的 lastmod 时间  (5)提高网站的抓取效率  参考: 如何最大限度地提高抓取效率 1、提高网页加载速度 页面测速工具: 2、移动端优化 拥有一个移动端用户体验友好的网站对于SEO来说是必不可少的。有两个原因: ① 谷歌采用移动优先索引-主要使用移动页面的内容进行索引和排名。 ② 移动体验是页面体验信号的一部分-虽然谷歌据称总是会“推广”最好内容的页面,但页面体验可以成为提供类似质量内容的页面的决定性因素。 移动端常见的 3 种问题: 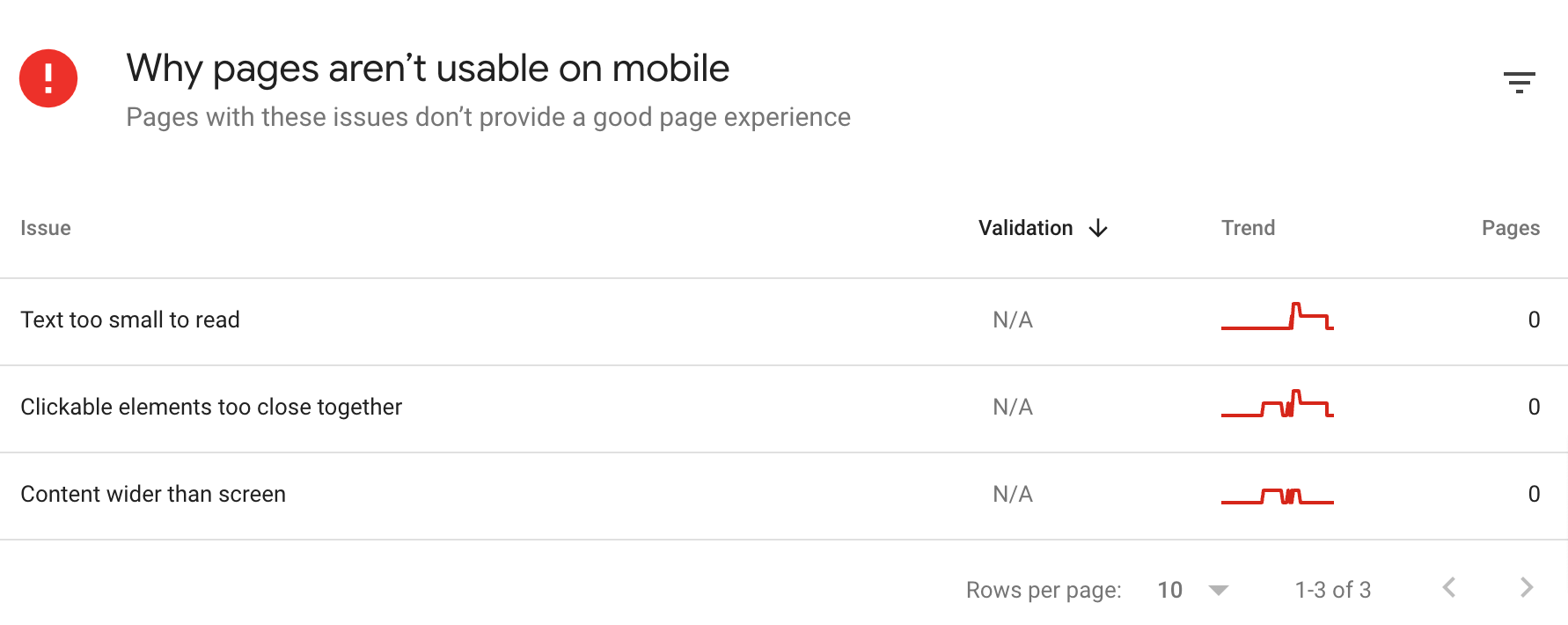 关于如何修复移动端问题, 具体细节可参考谷歌官方的 Mobile Usability report 五、Screaming Frog 爬虫配置及使用 SOP 前面提到我们是用 Screaming Frog SEO Spider 这个爬虫工具爬取网站的, 下面我会结合一个例子讲下怎么配置爬虫和使用爬虫. (1)配置爬虫 1、 基本配置 打开配置选项: Configuration -> Spider 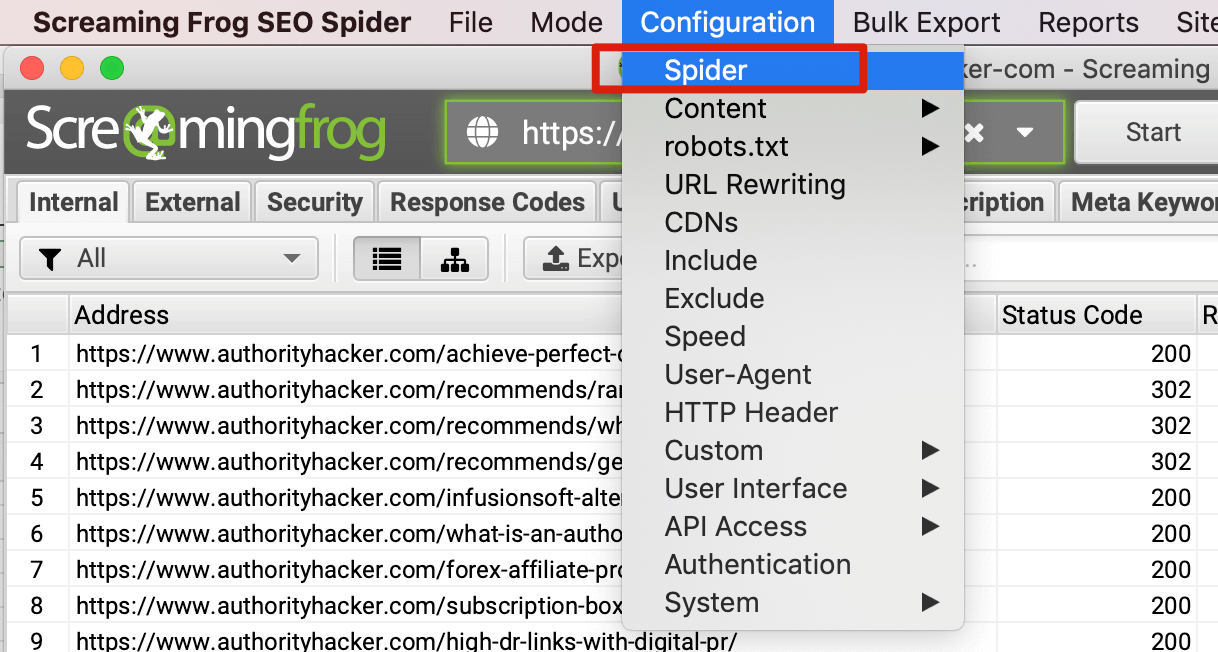 勾选这些选项 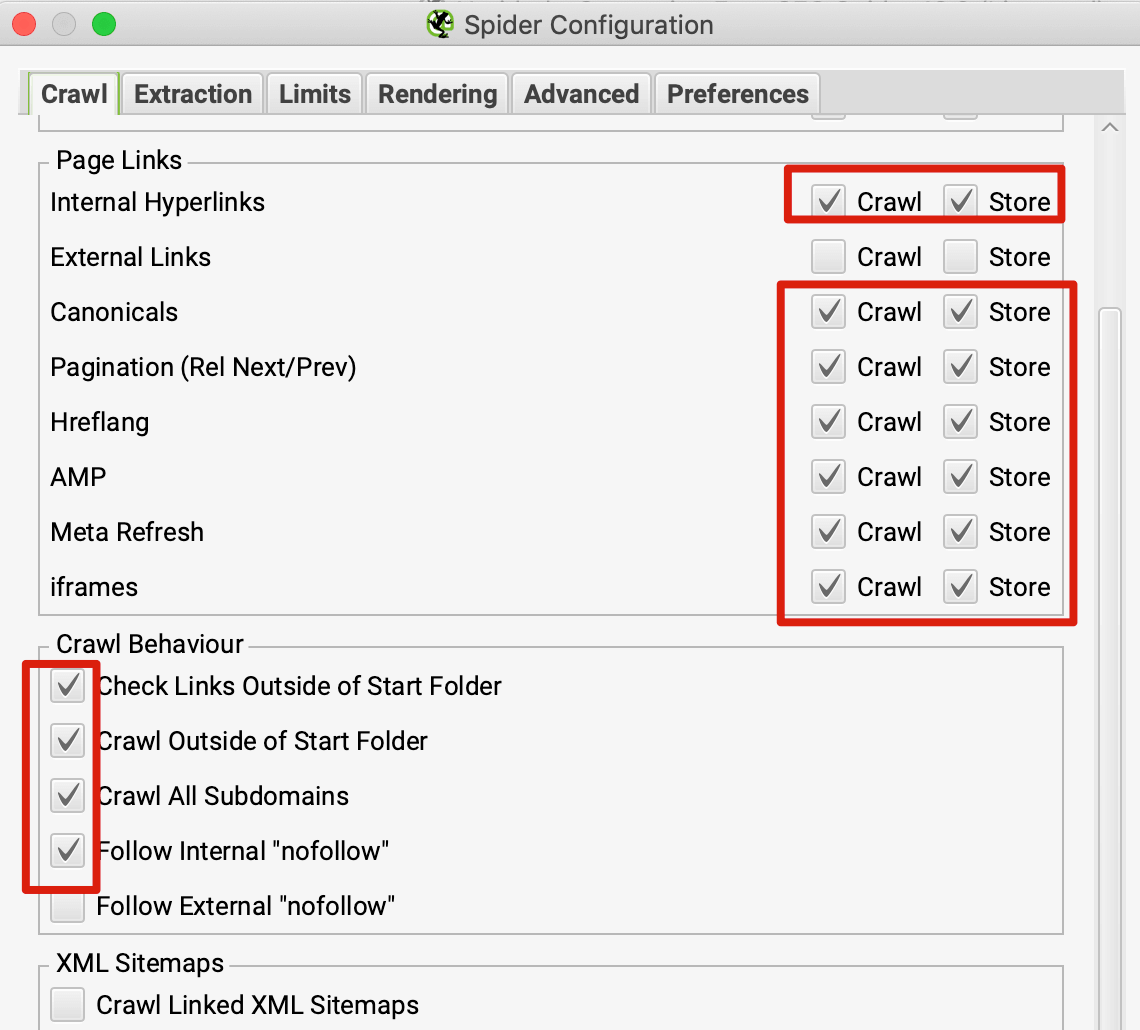 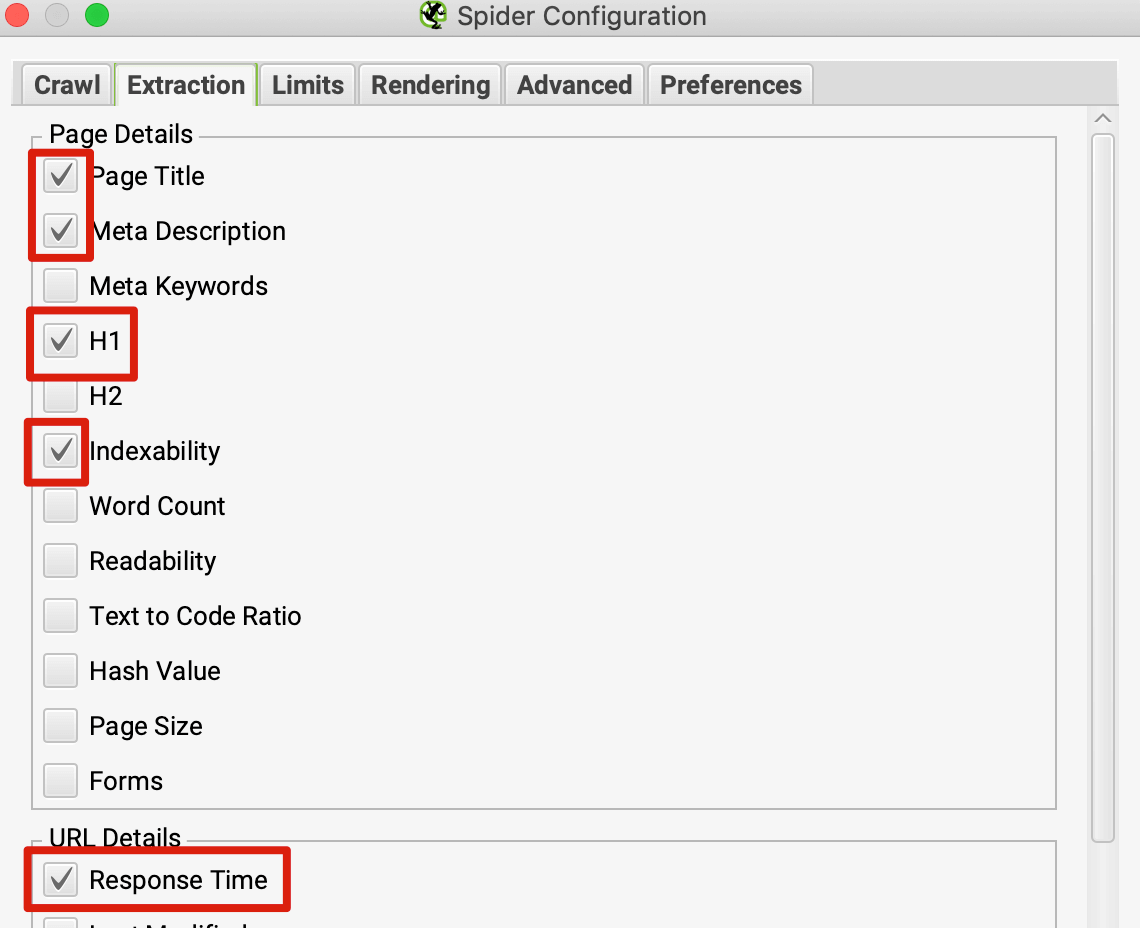 2、 忽略 robots.txt 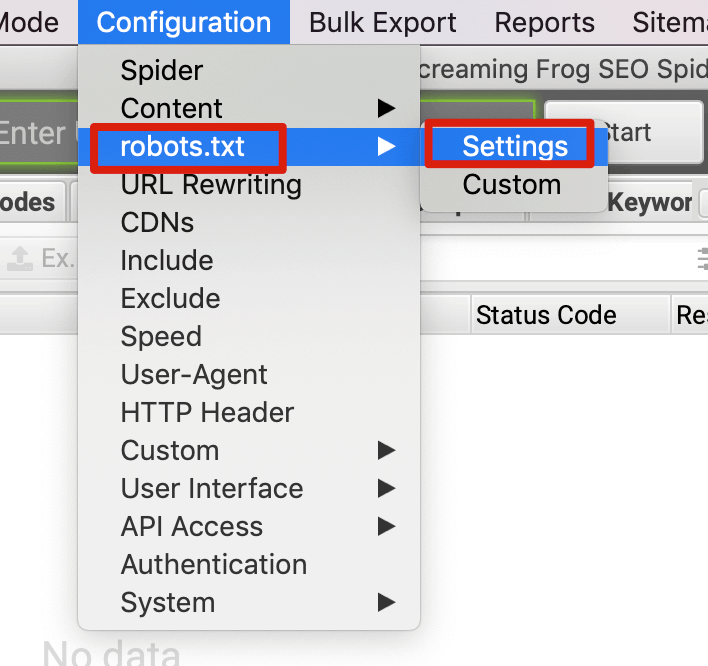 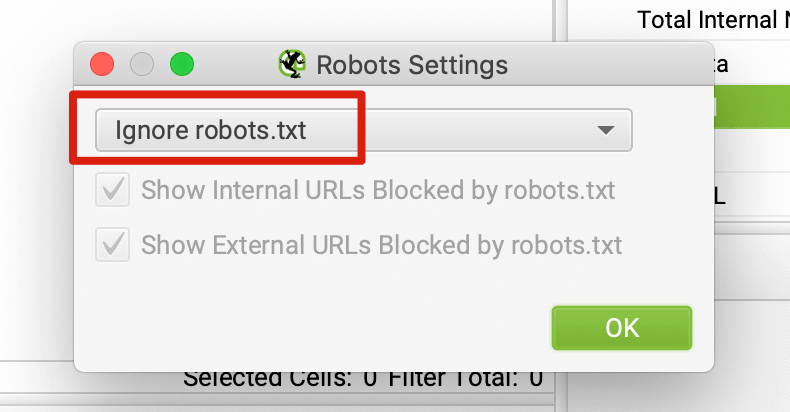 3、 设置爬虫速度  一般速度设置 10 即可 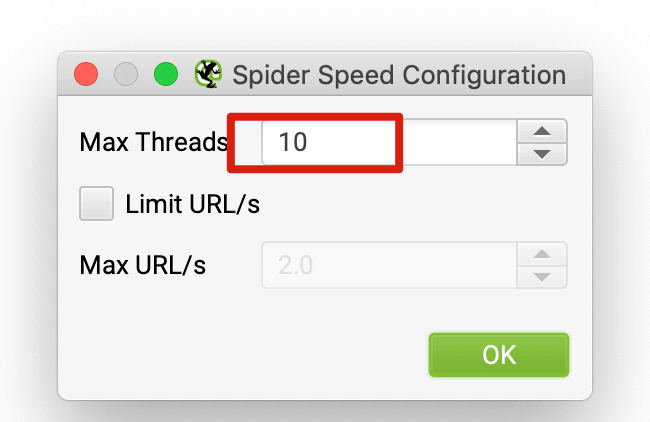 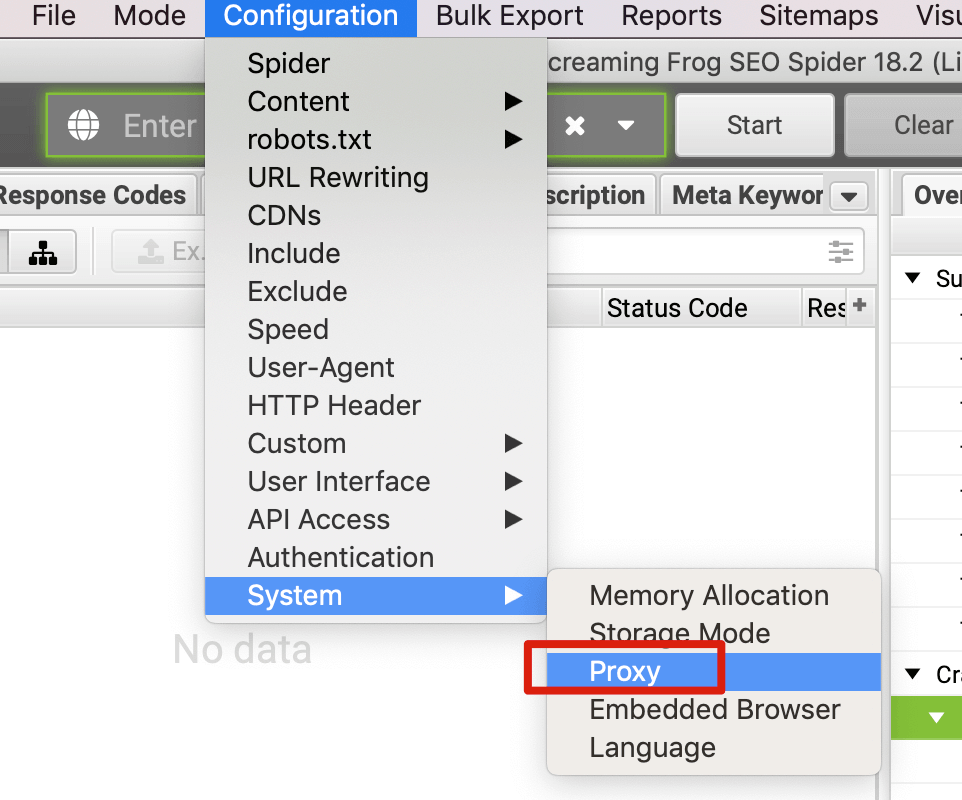 4、 设置爬虫保存路径 5、设置代理(非必需) 如果有的网站屏蔽了国内的 IP, 爬虫要通过设置代理才能访问 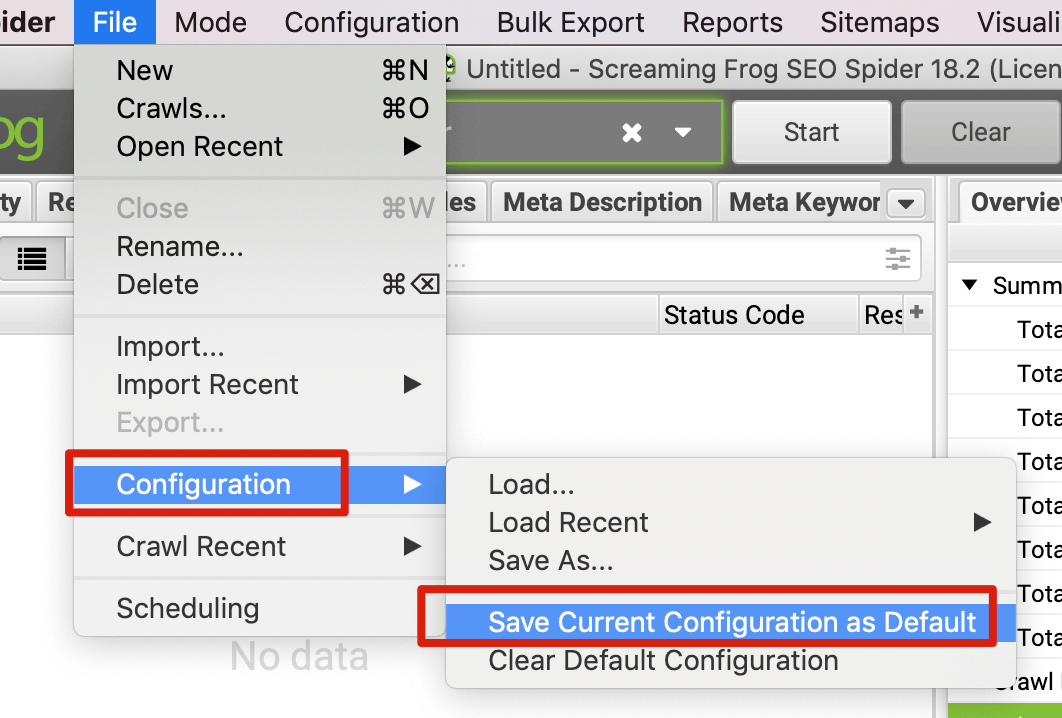 根据你的代理软件的 IP 和 端口设置代理  6、保存配置 保存当前配置为默认配置, 后面每次打开爬虫默认就是这个配置 (2) 爬虫使用步骤 1、 设置爬取模式 ① Spider 模式 顾名思义, 爬虫按照某个入口去爬网站, 一般选这种模式 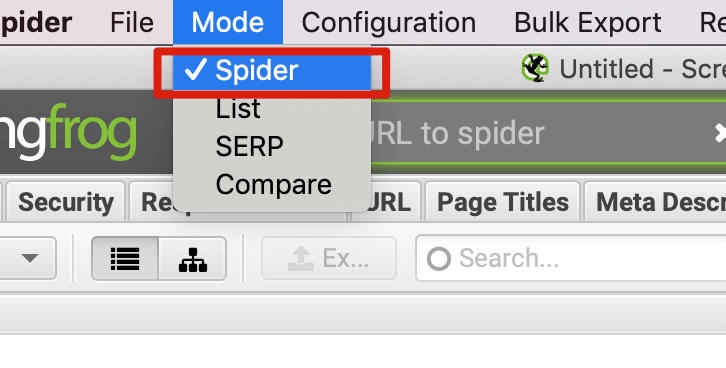 ② List 模式 爬虫通过给定的 URL list 去爬网站 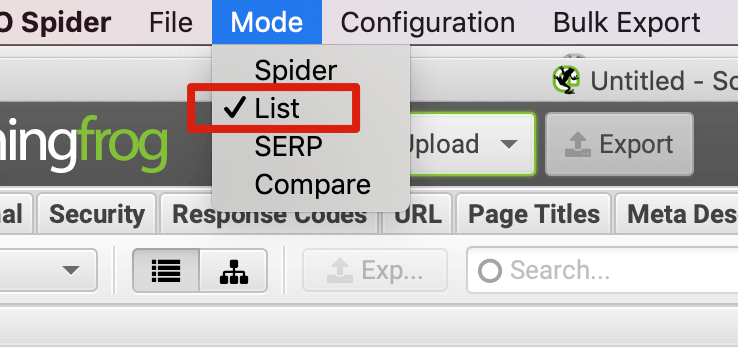 有下面 4 种方式导入 URL list 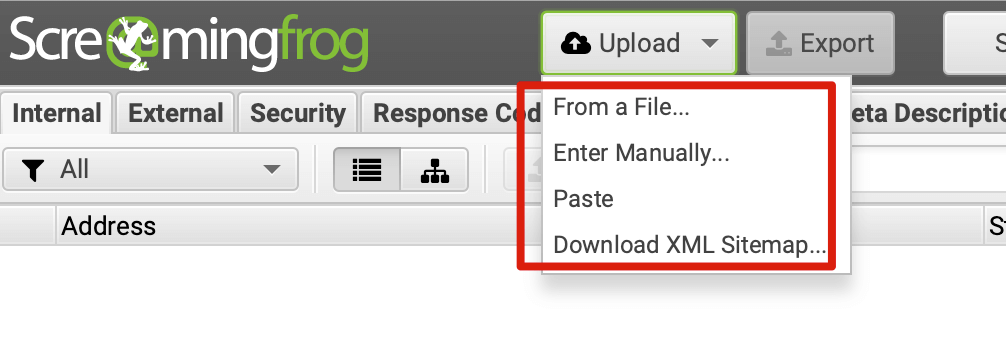 如果是爬某个 sitemap 里的 URL, 选择上面的 “Download XML Sitemap” 导入即可 2、设置过滤条件 一般设置 Include 或 Exclude 过滤条件爬取特定的页面, 如果是整站爬取, 则不用设置   3、检查爬虫爬取结果 ① 检查 3xx, 4xx 和 5xx 问题页面 一般检查 404, 500, 308页面 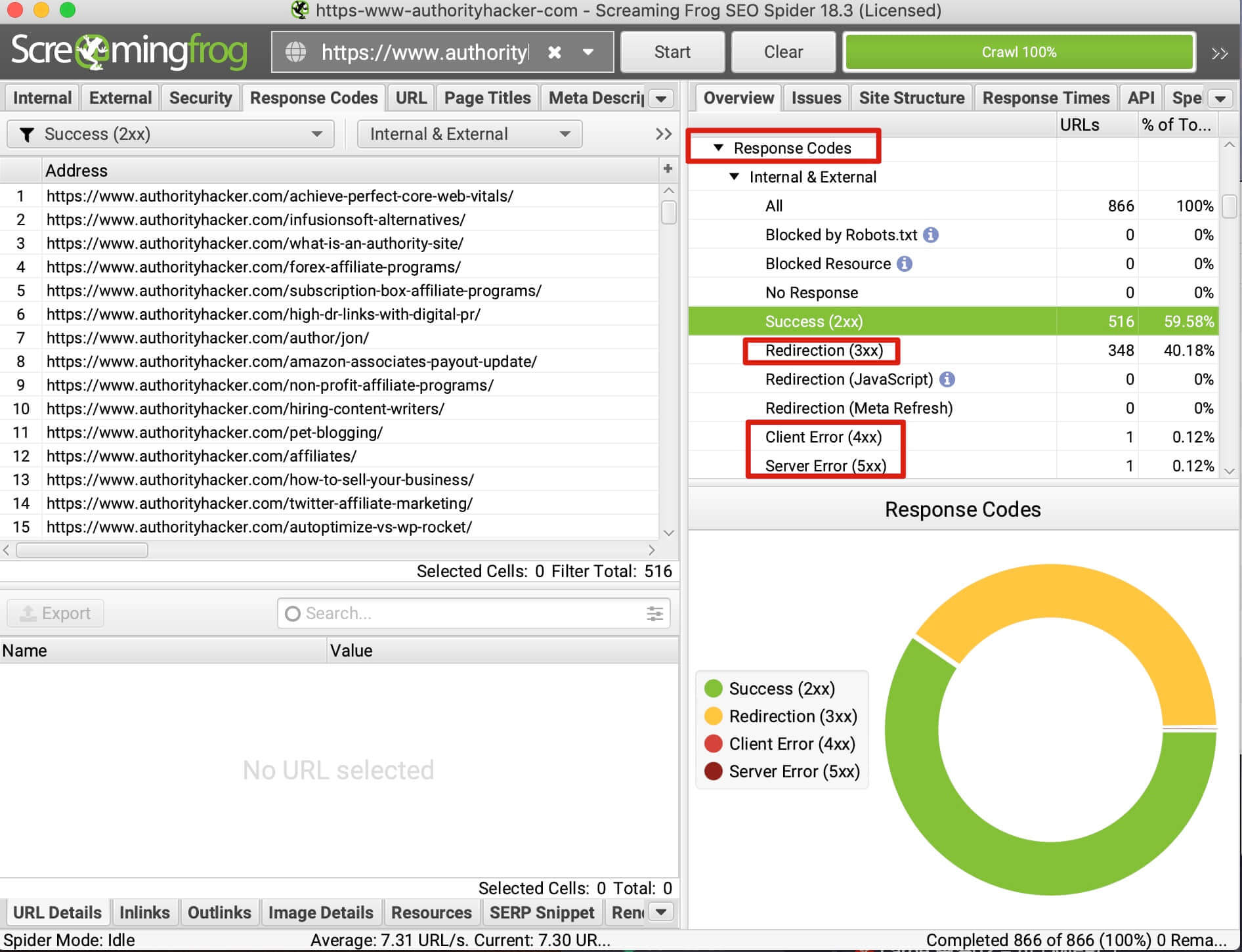 要查看某个页面的来源页面, 选择底部的 “Inlinks”, 其中 From 指当前页面的来源页面, To 就是当前页面, Anchor Text 就是当前页面的锚文本 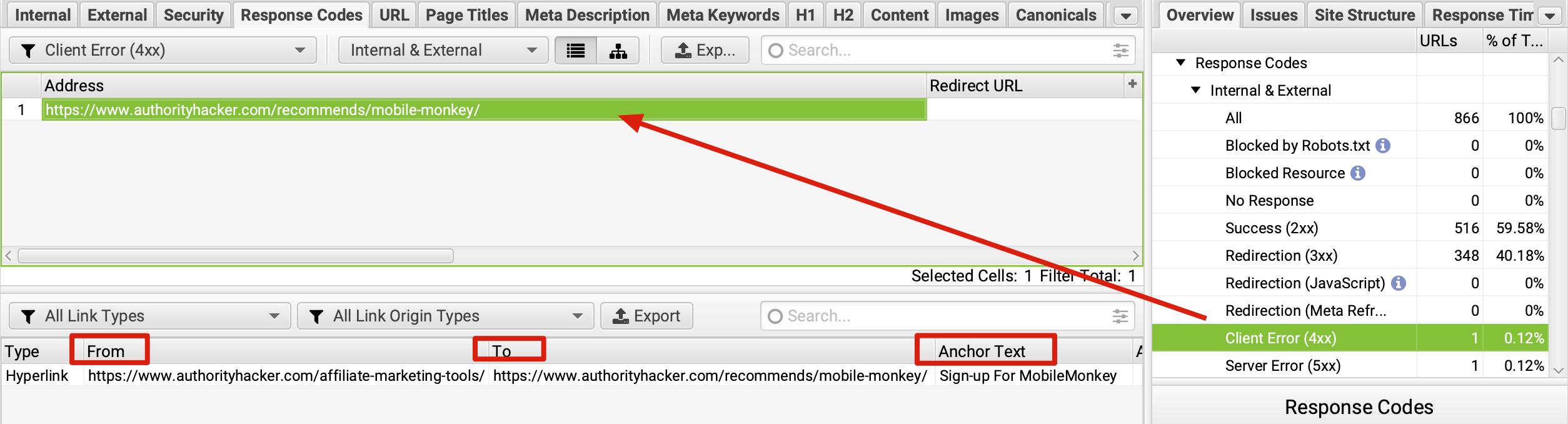 选择底部的 Export 按钮即可导出当前页面的来源页面及锚文本, 可批量导出对应页面的来源页面及锚文本 ② 检查 No response 页面 No response 的页面一般是网络问题导致的, 这种页面不多的话, 建议重新爬下( Re-Spider) 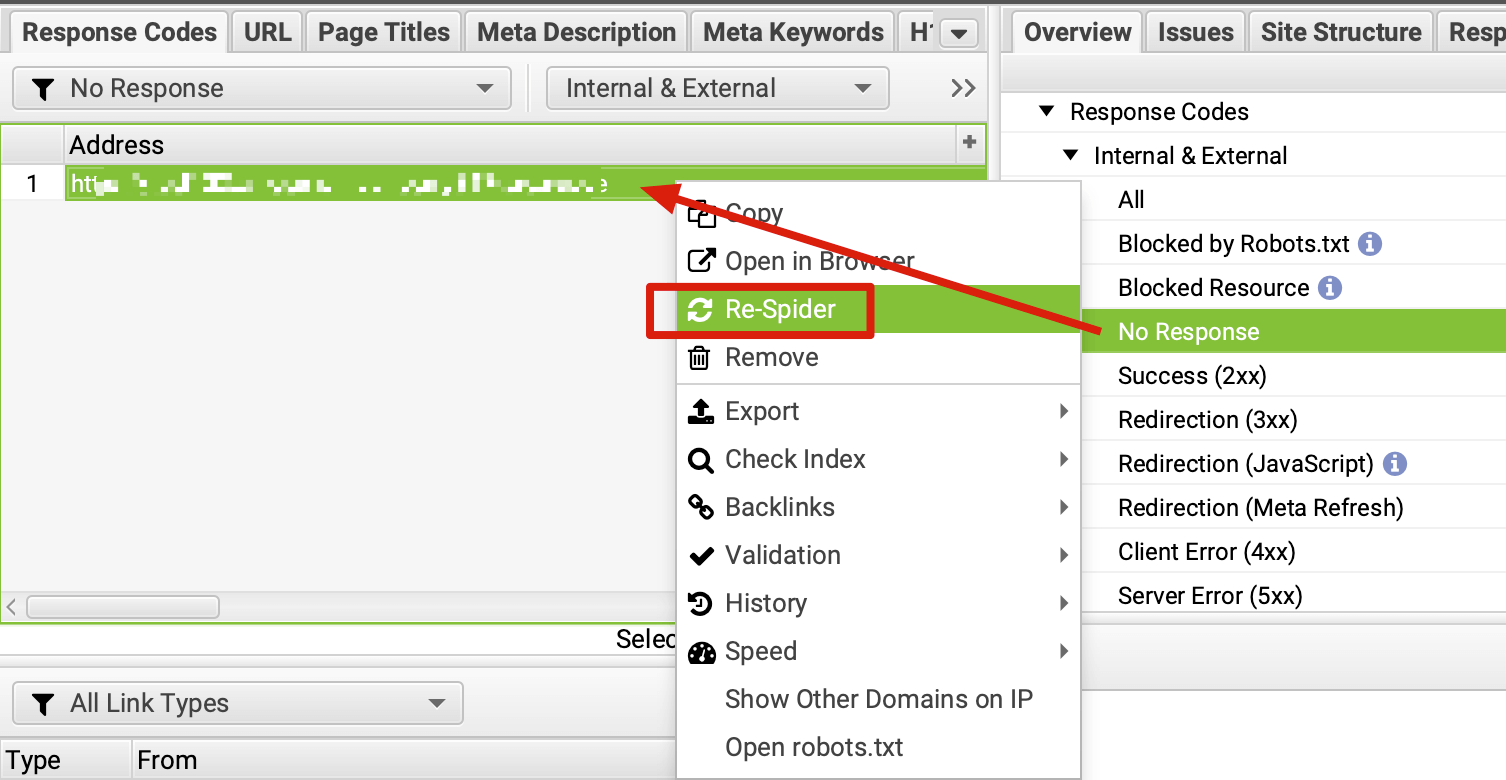 ③ 检查页面5元素
 六、Technical SEO 优化的一些技巧和工具分享 (1)检查网站添加的GTM代码是否生效 以这个页面为例, 在浏览器里点击右键选择 "检查" 选项进入开发者模式  按如下图右边的第 1, 2, 3 步操作即可查看该网站的 GTM 代码, 状态码如果是 200, 表示添加的 GTM 代码是生效的 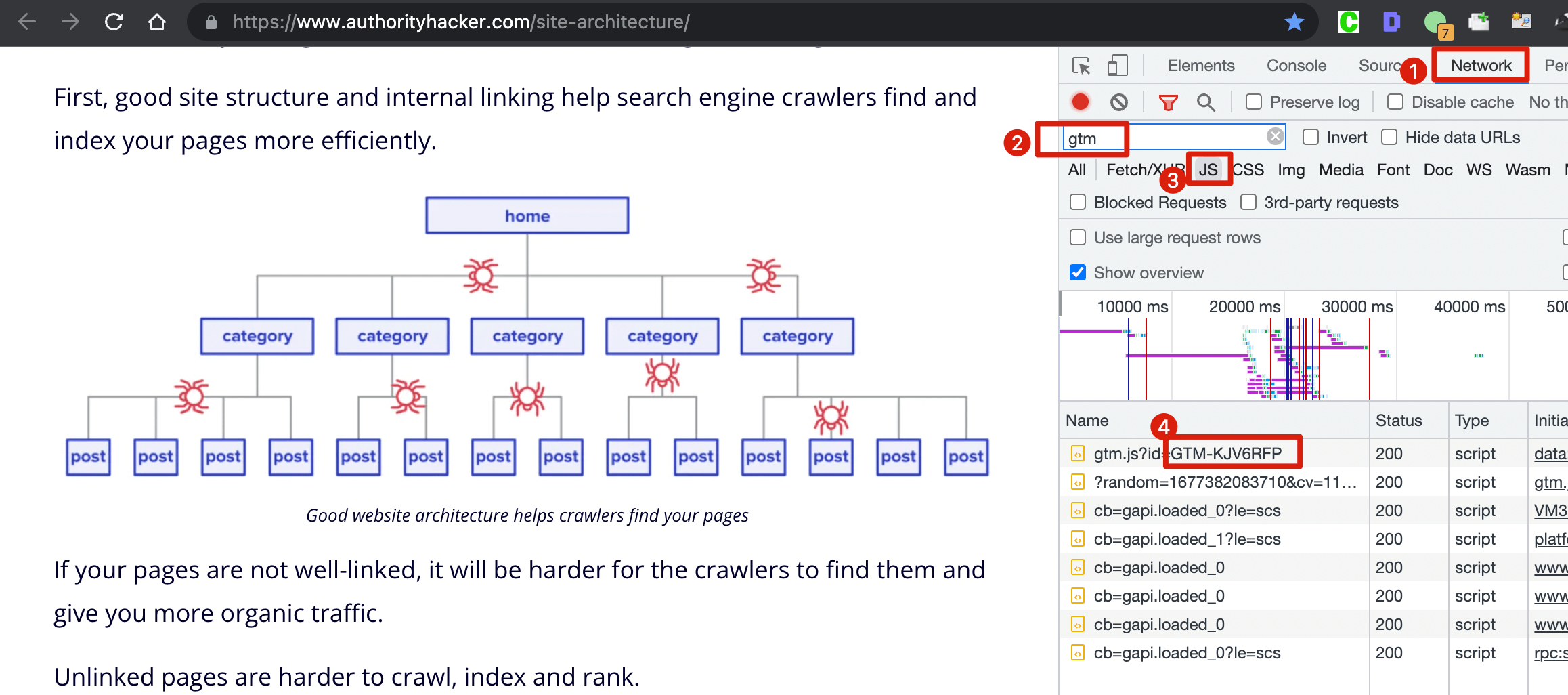 (2)Google Index API GSC 后台一天能提交的 URL 好像限制50条, 但是借助 Google Index API , 配置批量提交页面收录的工具, 1个站点一天最多可以提交200个 URL! 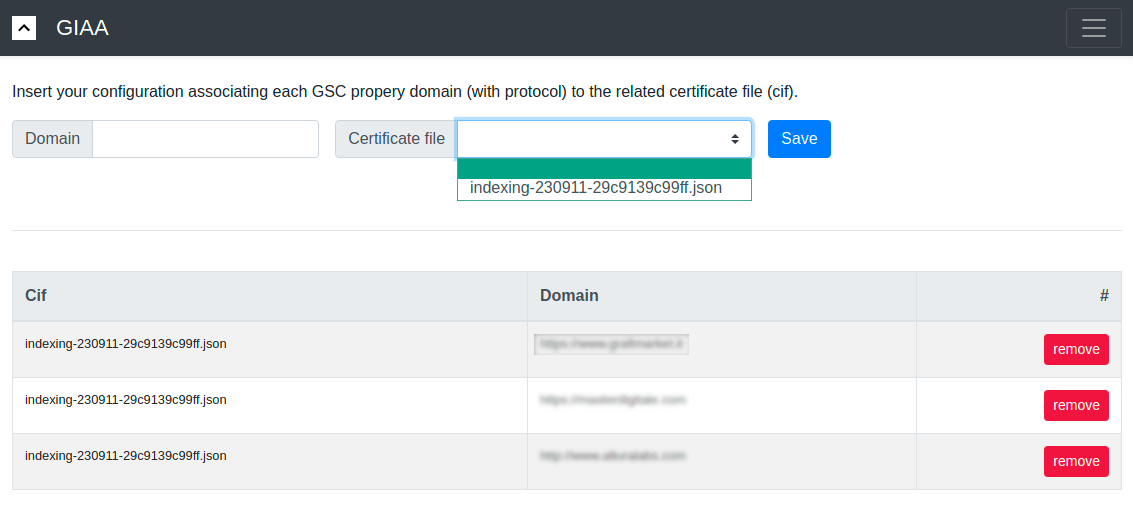 (3)借助 RPA 插件提高提交 sitemap 的效率 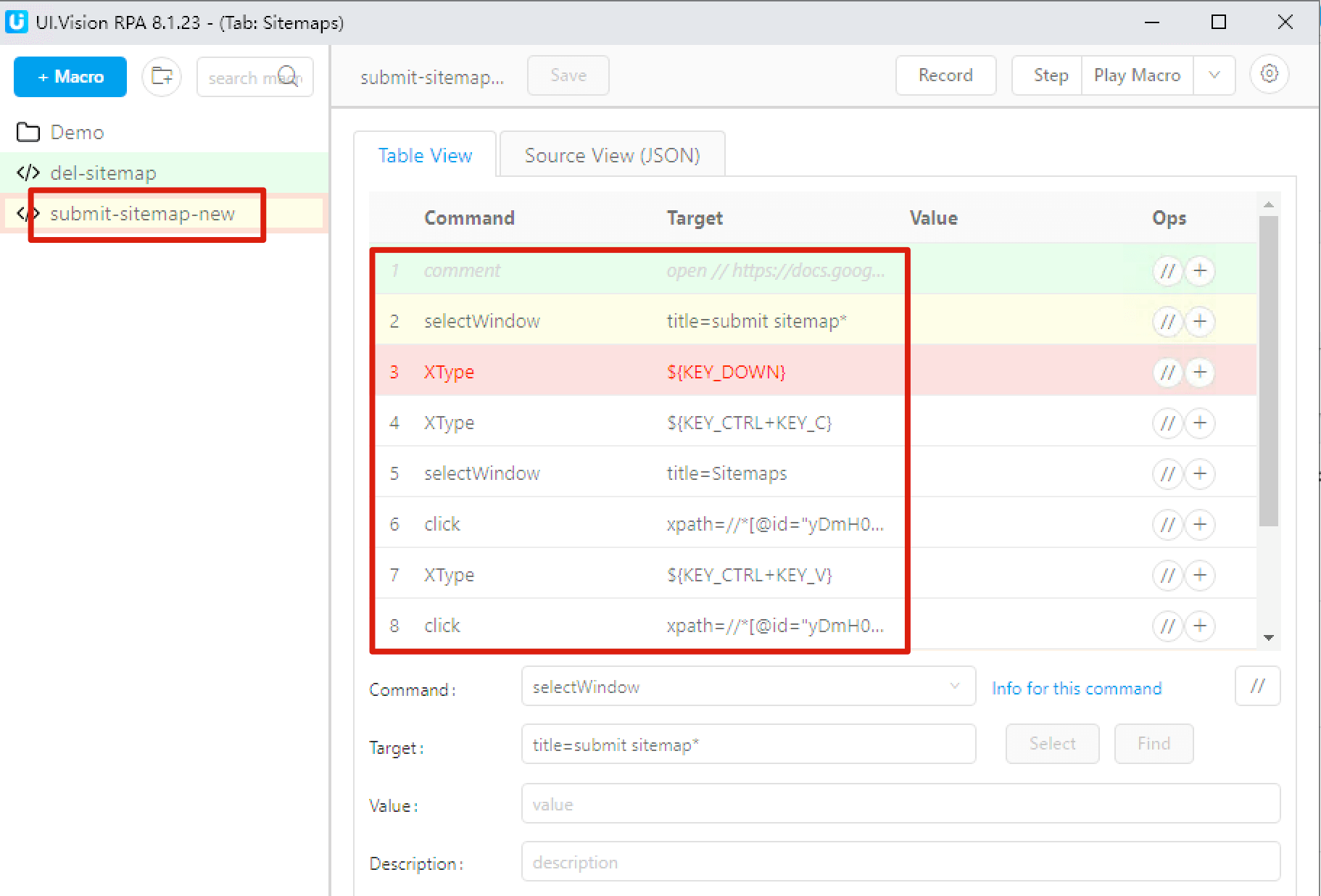 之前我们在 Google Search Console 后台提交 sitemap 都是人工手动一个一个提交的, 但是后面网站多了, 要经常更新并提交 sitemap, 人工提交效率太低, 后面我找到了一个 Chrome 插件: UI.Vision RPA , 这是一个 RPA 工具, 很多简单重复的工作可以用它处理, 我按照我们提交 sitemap 的流程配置这个插件后, 提交 sitemap 的效率至少提高了10倍! (4)如何批量检查 GSC 里的来源页面和来源的 sitemap 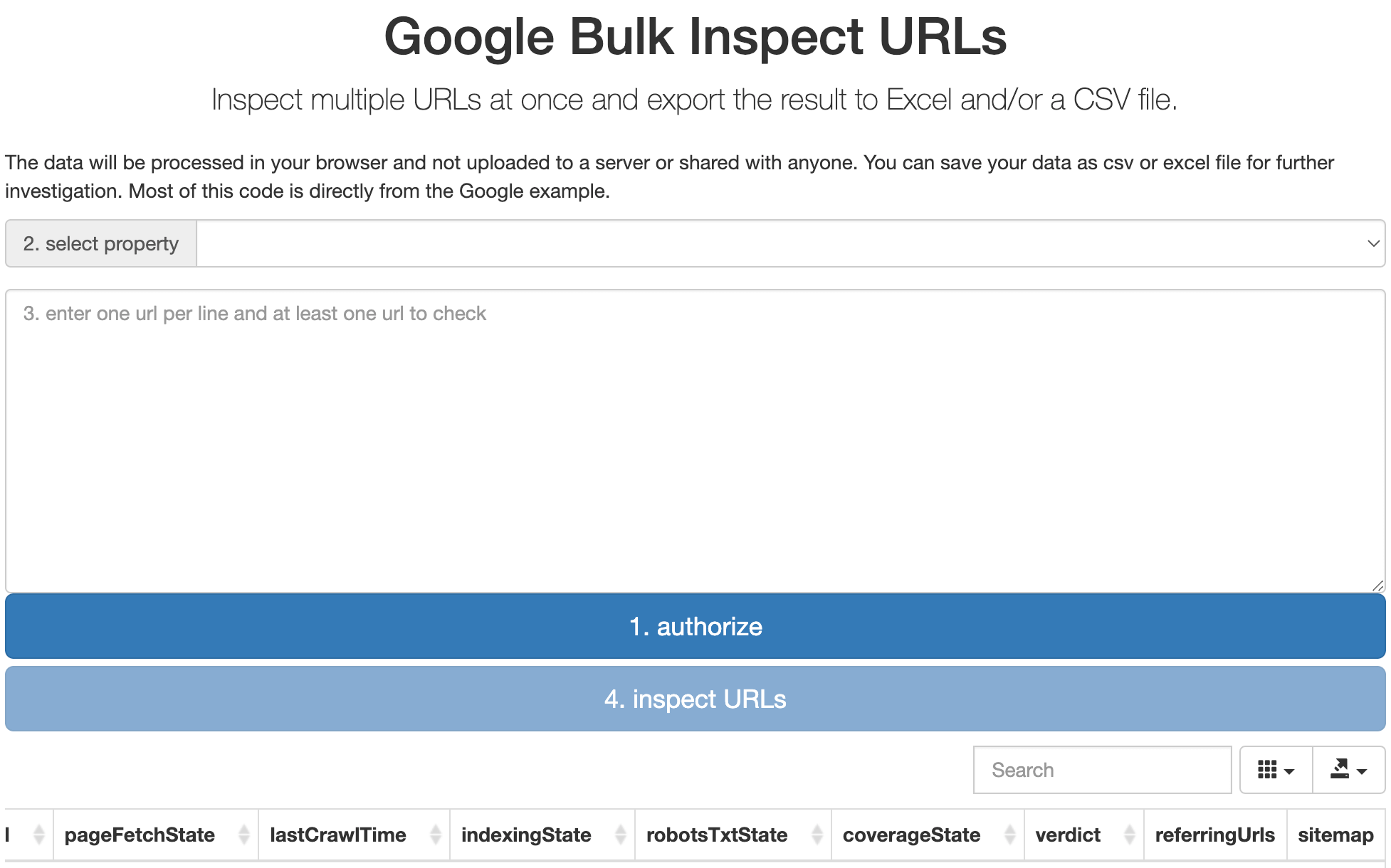 熟悉 GSC 的朋友应该都知道, GSC 后台查看某个页面的来源页面和 sitemap, 只能一个一个点击该页面详情后查看, 非常不方便. 现在借助这个工具Google Bulk Inspect URLs 即可批量查看来源 关于如何这个工具的介绍及使用说明, 可参考这篇文章 (5)一些检查工具 最后 这是我此次的分享,希望对大家有启发,有帮助,祝大家网运昌隆 |



最新评论